הבסיס של העבודה עם CLO במימוש צאט מבוסס LLM
בפוסט הזה אנסה להסביר כיצד עובד התהליך המרכזי בארכיטכטורת CLO , אך קודם כל חשוב מאד להדגיש שהיא לא מתאימה לכל בעיה בעולמות הנגשת המידע ב LLM , יש בעיות שבהן מימוש CLO נותן מענה מעולה ויש בעיות אחרת מתחום הנגשת מידע באמצעות LLM בהן הפעלת CLO אינה מתאימה
על איך לבחור את הגישה המתאימה לפתרון הנגשת מידע באמצעות LLM אפשר לקרוא כאן
טוב אז אחרי ההסתייגויות ואחרי שקראתם את הפוסט על התאמת פתרון מבוסס LLM לסוג הבעיה העסקית אפשר להתחיל 🙂
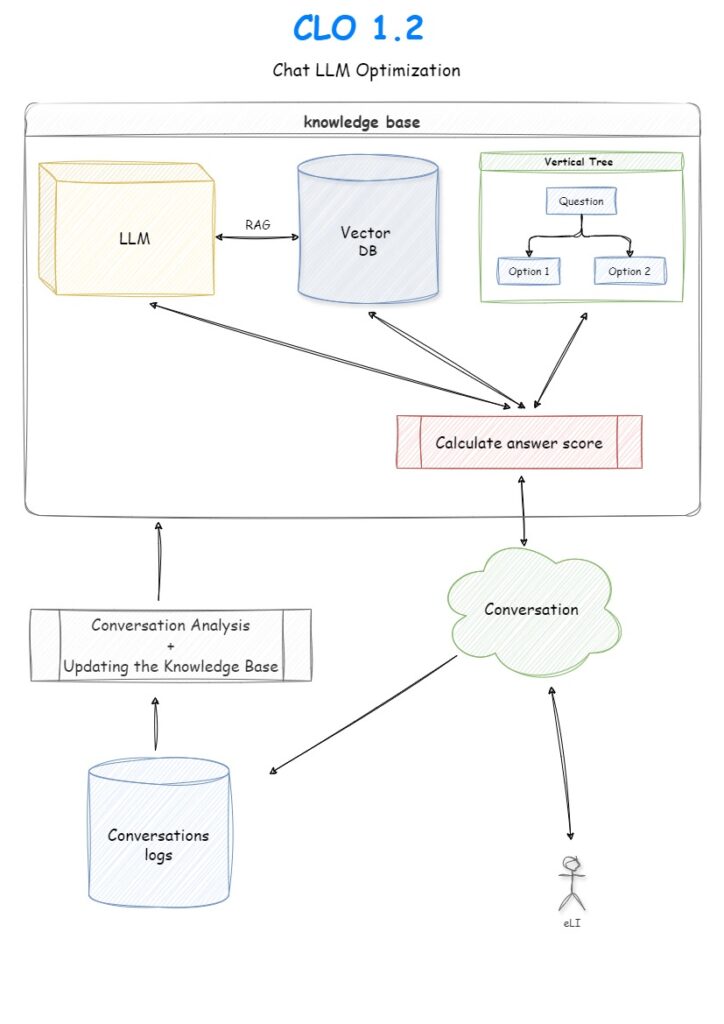
בפתרון שמימשנו בארכיטקטורת CLO הרכיב המרכזי הוא ה VECTOR DB – הצעד הראשון שאנחנו מבצעים בקבלת שאלה חדשה הוא שימוש ב VECTOR DB
ממש בגדול אנחנו לוקחים את השאלה ופונים איתה למאגר שאלות מאד גדול ומחפשים האם קיימת לנו שאלה עם אותה משמעות במאגר
וכאן נכנס הקסם של ה TRANSFORMERS , אמנם אנחנו לא פונים למודל שפה גדול ומג’נרטים תשובה חדשה, אבל המאגר שלנו ב VECTOR DB נבנה בצורה כזו שהוא יודע לייצג את המשמעות של התוכן ולהביא לנו את השאלה הכי קרובה במשמעות לשאלה ששאלנו וזה לא הכל אנחנו מקבלים גם ציון של עד כמה השאלות דומות.
אם שני המשפטים האחרונים לא היו ברורים , כדאי לקרוא את הפוסט “מה זה embedding ולמה זה כ”כ חשוב”
אם הצלחנו לזהות שאלה מספיק דומה במאגר אנחנו מחזירים למשתמש את התשובה לאותה שאלה.
ההחלטה אם התשובה מספיק דומה תלויה בצורה שבה אנו משווים את הדימיון בין הוקטורים
וקשורה גם לסוג הבעיה העסקית. כחלק מתכולות פיתוח הפתרון תצטרכו להחליט מה ה threshold המתאים לבעיה שלכם.
אם זה לא היה מספיק ברור אז כן, הכנסנו ל VECTOR DB מאגר ענק של שאלות ותשובות בתחומים שרצינו לכסות.
גם הנושא של איסוף השאלות מאד מעניין ואפשר לקרוא עליו בפוסט הערכות לביצוע פרויקט בינה מלאכותית בארגון מתי מתחילים?)
אז יש לנו מאגר שאלות ותשובות גדול ב VECTOR DB אנחנו פונים אליו עם שאלה חדשה, אם אנחנו מצליחים למצוא במאגר שלנו שאלה עם משמעות זהה אנחנו מחזירים את התשובה לשאלה, אם לא הצלחנו יש לנו כמה אפשרויות
1. ללכת שמאלה בשרטוט של ה CLO להשתמש ב LLM כדי “לייצר” תשובה מתאימה (בד”כ בשיטת ה RAG המפורסמת)
2. ללכת ימינה בשרטוט של ה CLO ולהציג שאלות סגורות שיעזרו למשתמש לדייק את המידע שהוא מעוניין להשיג.
מתי הולכים ימינה בשרטוט ומתי הולכים שמאלה? התשובה מאד ארוכה ומשתנה מאד בהתאם לבעיה העסקית אבל ממש בגדול
אם קיבלנו תשובות קרובות מספיק מה VECTOR DB אבל לא ברמת וודאות שמספיקה לנו כדי להחזיר תשובה השימוש ב RAG יכול לעזור לנו לדייק את התשובה ולשפר את המענה
ואז נלך שמאלה בשרטוט לכיוון ה LLM , אם לא הצלחנו לזהות שאלות או תוכן דומה בכלל אנחנו נפנה לחלק הימני בשרטוט ונשתמש בשאלות סגורות כדי להתקרב לתוכן שמעניין את המשתמש או להגיד לו שאנחנו מתנצלים אבל במקרה הזה אנחנו לא יכולים לענות. כדאי לקרוא את הפוסט איך מתמודדים עם אזורים בהם המודל שלנו לא עובד טוב